这是什么
本文记录了笔者使用Python语言对于微博社区管理中心中的举报不实信息进行爬取,使用的模块为selenium。文章详细记录代码的含义以及最后给出所爬取的json数据。
具体实验过程
提醒
如果要亲自实践的话一些注意事项写在前面:
微博一个IP一天只能访问200次不实信息,所以要准备好多个IP进行多天的操作。
动态页面捕获
Selenium模块通过驱动浏览器能够直接对网页浏览,所有的数据都在网页的标签内,在这样的情况下我们可以直接通过对标签定位进行数据爬取。
同时微博管理社区中心的反扒取机制是需要用户登录之后才能够对网页进行浏览,于是我们可以使用模块驱动浏览器后自行人为在浏览器中先对微博进行登录这样我们通过模块直接对微博社区管理中心进行爬取。
数据爬取建议使用Jupiter notebook而不是纯Python文件,这样可以减少对于页面的请求次数避免反爬取措施,而且能够多次尝试找到正确的标签。
from lxml import etree
from selenium import webdriver
import requests
import time
import re
import json
import osbro = webdriver.Edge(executable_path='./msedgedriver.exe')以上指令打开浏览器后,在该浏览器中人工登录微博账号。
爬取页面描述及要求数据
打开实际的网页页面我们可以发现,平台提供了500页的谣言信息可以爬取,每页有20条信息。页码可以直接通过url的最后一个参数进行修改访问。
每页的20条信息分布在div(@id=pl_service_showcomlpliant)的tr中。我们一次可以获取一整页的20条tr的列表。
然后通过列表中的信息以及访问列表中的谣言处理url爬取原文。
打开谣言处理url后对于谣言原文的爬取有3个方法:若页面有’原文‘,则再点进’原文‘微博页面进行文章爬取。若页面有’查看全文‘,则对于’查看全文‘的部分的标签value属性爬取。若都没有,则直接对橘色方框的文字进行爬取。
所以爬取分为三层:
一层对平台一页20条进行爬取,
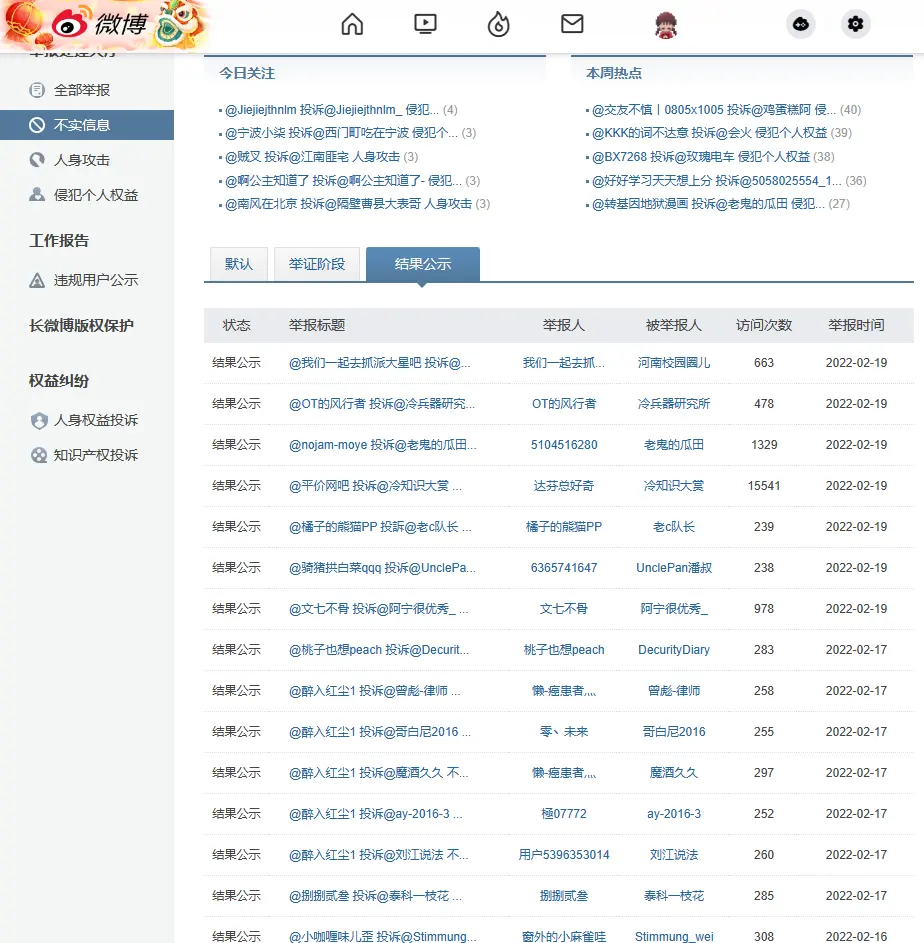
二层点进20条中每一条,
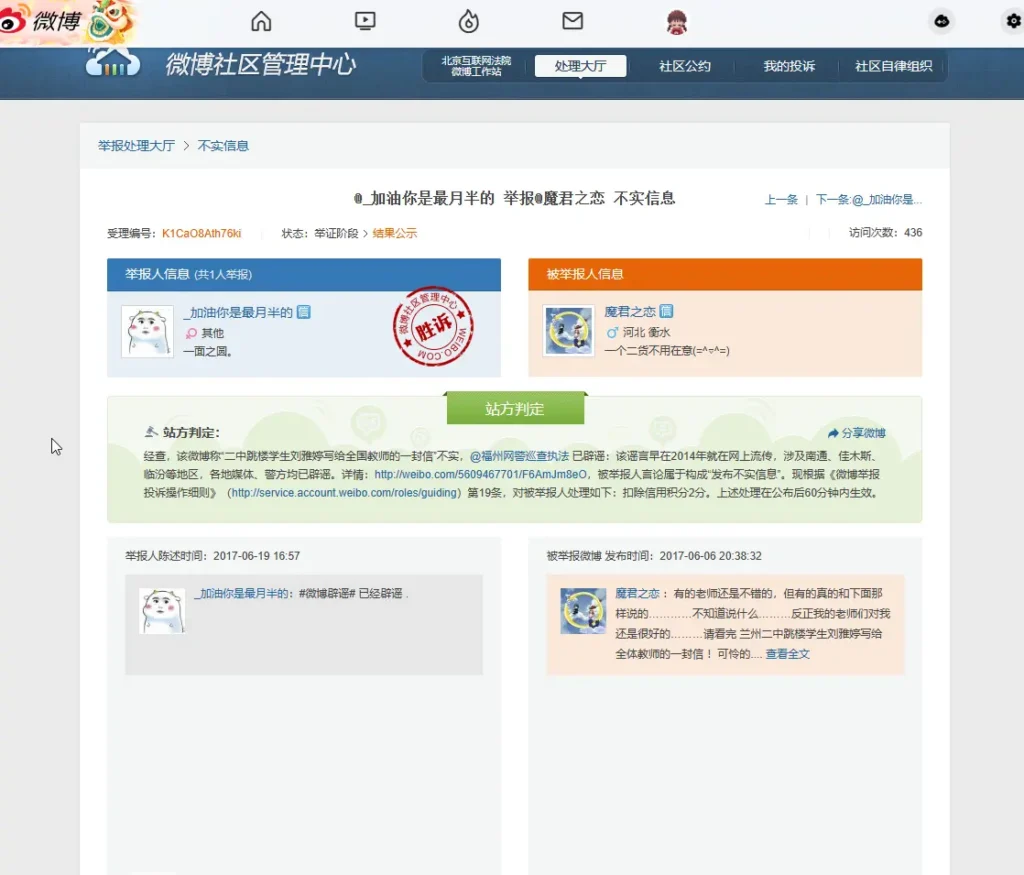

三层若需要原文则点进原微博进行爬取。
爬取微博服务平台公开的不实信息,在当前文件夹建立rumorJson文件夹,每一页20条信息以json形式存储到页数为文件名的文件中 (github.com)
通过以上代码完成:每一页的20条谣言信息被写入一个页码为文件名字的文件中。
之所以这样写是因为微博还有一个神奇的IP反爬取机制,测试下来每一个IP每天能够点开的不实信息只有200条,也就是10页。所以把每一页分别存储避免爬取到一半程序宕机。每爬取完10页后换一个IP然后接着爬取。(所以j每次只能取10个数)
最后对于爬取到的500个json文件进行一定的整合处理就得到了一个2017年–2022年的微博谣言数据集了。
后话
这是笔者在研究谣言辨识处理的时候对于谣言爬取做的一些前置工作。在笔者20多年的互联网居住经历来看,这个大互联网已经越发不是正常居民能够居住的地方了。再也没有纯天然的话题,再也没有自发的热点,有的只是趋利的诱导和煽情。哪怕是现在的谣言数据集,也没有之前2017年前的那批数据集质量高了。
互联网究竟给我们带来了什么?这个问题在现在任何人都无法脱离互联网,并且流量为利润的时代值得我们去思考。远方发生的事情与我有什么关系?我为什么要为一个以前都不知道的事情倾注感情?在信息纯度不断被稀释的当下,究竟什么才是真的?
我非常向往Internet overdose里面的断网结局,整个互联网被弄得一团糟,网民开始自发退出互联网,但我也知道这样的事情是不可能的,而且是越来越不可能的。
只能想要让更多人知道:没有任何什么东西比你的身边环境更值得你去关注的。